Conclusion
Summary of Analysis
Technical interviews, assessments, and the necessary preparation for job applications is an integral part of securing a career in the tech world, specifically fields such as data science, software engineering, data engineering, etc. The pressure that job applications puts on those seeking a new position naturally generates content: content regarding interview preparation, the application processes at certain companies, the skills necessary and desirable to secure a particular role, and more. This is especially prominent for the younger generations, who utilize online platforms for discussions, debates, help, and more. Content is data, and data can be gathered and used to find solutions and/or gain more insight. Consequently, Reddit is a key data source to gain more insight into the world of technical job applications. The work done throughout this website heavily focuses on gaining insights from the Reddit data to better understand the discussion regarding this topic online. Various forms of analyses were conducted to achieve this goal.
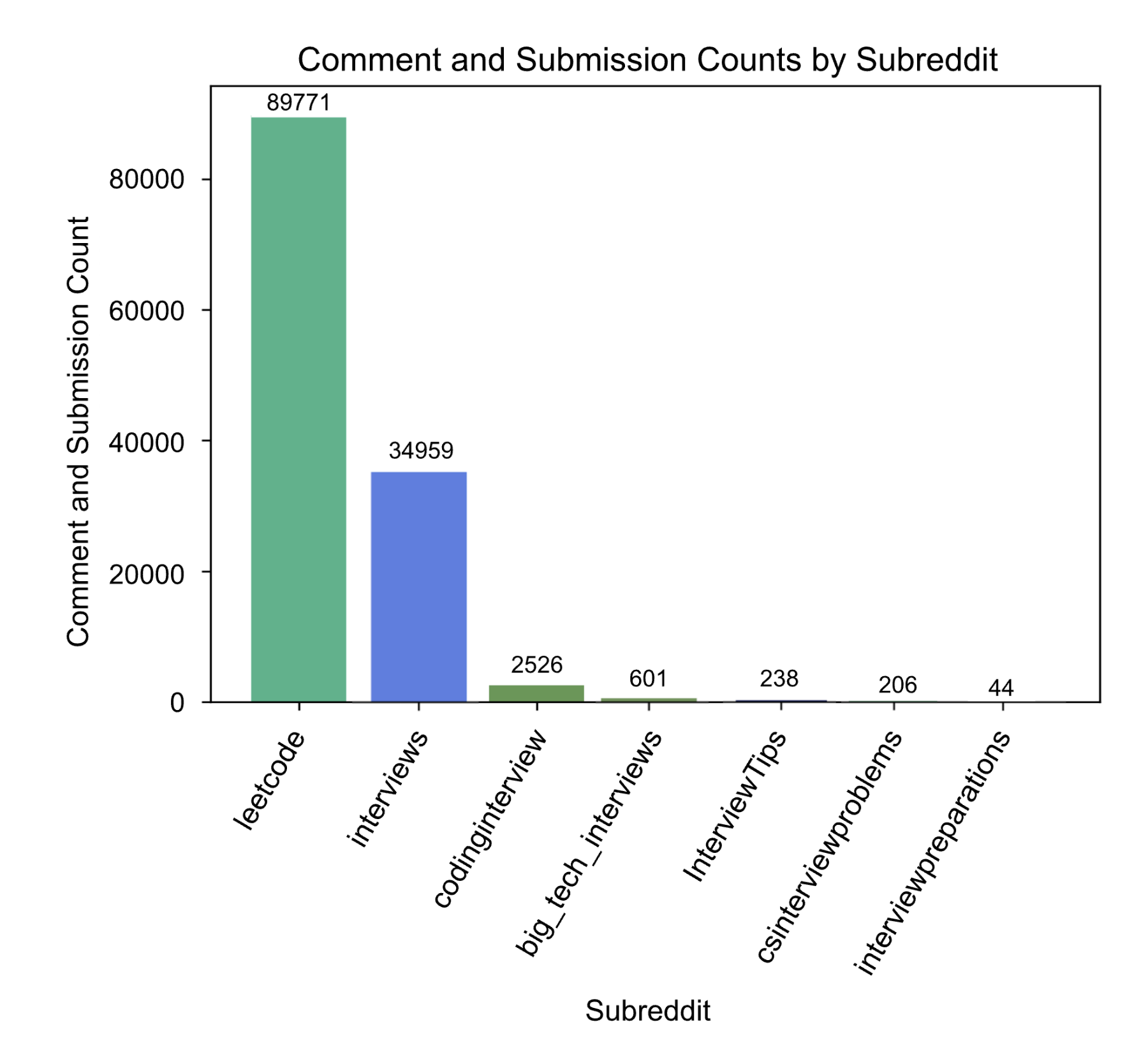
Through exploratory data analysis (EDA), the provided Reddit data was filtered down to contain only subreddits with posts falling under the topic areas of technical interviews, coding practice, general interviews, and more. The barplot below displays the specific subreddits used to filter the data and the number of posts falling under each. Even with this refined data set, the overall size warranted the use of big data methods and cloud computing with AWS in order to complete the outlined tasks. With these methods, the data was processed in order for further analysis to be conducted, mainly relating to natural language processing and machine learning. In addition, visualizations were used not only in the EDA tab but throughout the website to capture the progression of the analysis and display insights at each step in a clear, visual manner. Finally, an external data set regarding compensation for popular companies was gathered, cleaned, and merged with the existing Reddit data to further the analysis.
With the Reddit data being largely text from the posts and comments, there was a multitude of ways to leverage natural language processing techniques to gain further insight from the data. Searching the text using regular expressions allowed the creation of new variables. The table below summarizes the number of times each of the new variables were tagged out of the Reddit comments. The new variables were checking for comments regarding general technical areas, asking for help, asking questions, and mentioning one or more of the FAANG companies. Please see the NLP tab for further details on the data tagging and regular expressions used. Finally, sentiment analysis was used to gain an understanding of the emotions surrounding the discourse behind searching for jobs and sharing interview experiences. The results showed that Reddit is a safe space for this type of discourse with positive sentiment overwhelmingly outweighing negative and neutral sentiment.
| REGEX | TRUE | FALSE |
|---|---|---|
| Technical Comment | 20955 | 85268 |
| Comment Asking For Help | 8969 | 97254 |
| Comment Asking A Question | 21703 | 84520 |
| FAANG Comment | 3797 | 102426 |
Taking the natural language processing analysis one step further, machine learning methods enabled deeper insights into the distribution of topics, themes, and usefulness covered in the Reddit posts. Posts were deemed useful, semi-useful, or not useful based on a theoretical system of classification. A model was able to predict these classifications on unseen Reddit posts with some accuracy, but left room for improvement due to the highly-efficient but imperfect theoretical classification system. Other machine learning methods revealed three primary topics among the collective Reddit post text: (1) interviewing advice, (2) technical and computer programming advice, and (3) technical interview preparation advice. Although the third topic appears to be a mix of the first two topics, further clustering analysis reaffirmed this distinct separation of themes throughout the Reddit text.
Final Thoughts and Next Steps
Overall, the analysis concludes that Reddit is a dependable source for aid and insight into job searching and interview preparation. While analyzing the accuracy of claims made on Reddit fell outside the scope of this analysis, the analysis did affirm that the user-shared content on Reddit is largely on-topic, positive, and useful. If given more time and resources, future work on this analysis would explore ways to leverage machine learning methods to analyze accuracy and filter out posts that do not meet a desired level of relevance, positivity, and usefulness. Because the job market is constantly changing, these results could be streamlined with a live feed of Reddit posts to keep insights topical for anyone in the midst of applying and interviewing for jobs.