Conclusion
Our robust exploration of subreddits gave us a holistic understanding of the nuances of analysing and interpreting big data, particularly in the context of politics, finance, and economics. Through exploratory data analysis (EDA), natural language processing (NLP), and machine learning (ML), we gained insights into the trends, sentiments, and important features related to our data.
The exploratory data analysis (EDA) of Reddit’s political and economic subreddits offered a comprehensive view of online political and economic discourse, significantly enhancing our understanding of user behavior and the dynamics within these online communities. Our preliminary findings indicate that r/Conservative is the most active political subreddit, with a high number of posts and comments, and a strong resonance with its audience, as evidenced by its high average post score. In contrast, r/AskPolitics stands out for its diversity, suggesting a broader user base. This analysis also uncovered interesting patterns, such as Thursdays being the most active day for posting across various subreddits, and a general decrease in posting activity as the year progresses, aligning with common online engagement trends.
In delving deeper into the content, we found that post titles are more indicative of subreddit themes than post bodies, which are often links to external articles. Additionally, incorporating U.S. GDP data revealed a correlation between economic conditions and engagement levels on r/Economics. During economic downturns, there was a noticeable increase in subreddit activity, with a corresponding decrease in average post scores, indicating that users turn to these online communities for discussion and information in times of economic uncertainty. This EDA thus provides valuable insights into the patterns and preferences of Reddit users, particularly in the realms of politics and economics, offering a lens into how online discourse mirrors and reacts to real-world events.
Next, looking at our Natural Language Processing (NLP) section, we focused on analyzing trends in submission posts and comments across nine Reddit subreddits. Utilizing the johnsnowlabs sparkNLP library, this section delved into sentiment analysis, assigning each submission and comment a sentiment category: positive, negative, or neutral. This approach unveiled significant overlaps in key words across both political and economic subreddits, indicating shared themes and concerns among these communities.
A critical aspect of the NLP analysis was the exploration of sentiment trends within these subreddits. Interestingly, subreddits like r/Conservative, r/Libertarian, and r/centrist demonstrated a predominance of positive sentiments in comments, whereas r/Economics and r/Liberal leaned towards more negative sentiments. This polarity was also evident in submissions, with r/AskPolitics and r/Conservative featuring higher negative sentiments, while r/Economics and r/Liberal showed more positivity. These findings suggest a complex landscape of online discourse, where positivity prevails, but negativity and polarization are still significant. The scant presence of neutral sentiments implies that Reddit users in these communities generally take definitive stances on issues rather than remaining neutral.
Furthermore, the integration of external data from the FRED python package enriched the analysis, particularly in the r/Economics subreddit. The frequency of terms like “recession” spiked in tandem with major economic events, indicating the subreddit’s responsiveness to real-world economic shifts. This highlights how online discussions are not isolated but are deeply intertwined with global events, reflecting and reacting to them.
r/Economics Submissions vs GDP
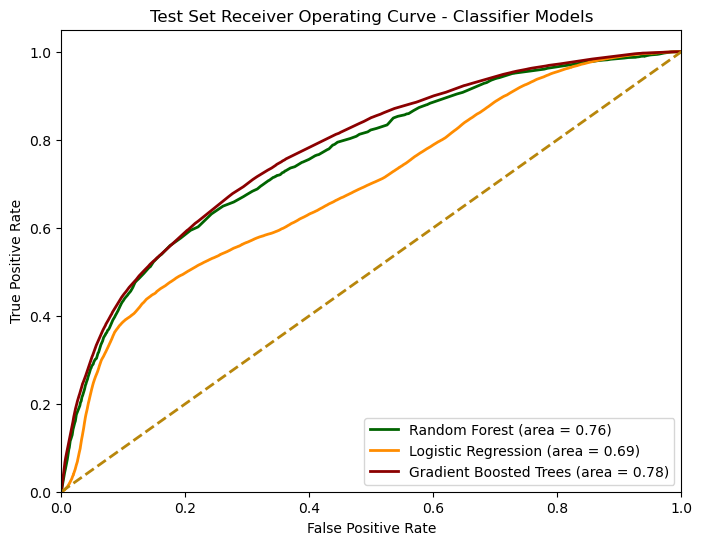
The Machine Learning (ML) analysis employed regression, classification, and clustering to predict submission scores, comment controversiality, and segment submissions based on content, respectively. The regression analysis revealed that the score of a submission is mostly explained by the day it was posted, the length of its title, the subreddit it belonged to, and whether it was gilded (number of times it received Reddit gold). The classification analysis unveiled that although only 7% of comments are tagged as controversial, Logistic Regression predicted more of them correctly than the ensemble models, but at the expense of misclassifying more non-controversial comments as controversial. The clustering analysis revealed that submissions content of all nine subreddits has considerable overlap, making it difficult to segment them based on content and other features.
Next steps
Our project has several limitations, related to our data and analysis, that can be addressed in future work. First, our project is catered to the U.S audience and we treat our findings to be native to the U.S; however, Reddit is open to the world, so there will be a few comments and submissions that were posted outside the U.S. Although this did not hamper our work, we do admit some bias may be present in our findings. To treat this issue, we could broaden the project to provide a more global perspective on online discourse by expanding the analysis to include subreddits from other countries.
We could also focus on more specific and significant topics, such as the COVID-19 pandemic, which has had a profound impact on the economy and politics. This would allow us to explore how online discourse has evolved in response to this global crisis. Additionally, in terms of specific implementations in the project, given greater computational power, training a sentiment model ourself specific to our given dataset may prove to give more insightful results, rather than relying on a pretrained Twitter model. Furthermore, for both regression and classification, it may be worth creating stacked models and conducting hyperparameter tuning to hopefully yield better results.
Appendix
This section expands on the updates we made to our analysis since the intermediate deliverables. Specifically, we added a new section on Machine Learning (ML) to include clustering analysis of submissions, and we incorporated professor Amit’s feedback on diving deeper in our shared user interaction analysis, as showcased in the EDA section.
Although the ML section was complete with the submission of the intermediate deliverable, we were still looking forward to adding a clustering analysis of submissions, given some overlapping topics from the LDA Topic Modeling section. It also gave us an opportunity to display unique visualizations, including the Principal Components by Subreddit, the Silhouette Score by Number of Clusters, and the performance of KMeans, all of which augmented our understanding of subreddit content.
Professor Amit’s feedback on our EDA section was also very helpful, as it encouraged us to dive deeper into our analysis of shared users across political subreddits. We were able to add a new LDA Topic Modeling visualization and a table summarizing the topics. This is further discussed and showcased in the Discussion section