NLP
Executive summary
This section outlines the NLP procedures conducted for the project. We performed a comprehensive sentiment analysis on Reddit’s r/AmItheA*hole, revealing a dominant negative sentiment across posts, regardless of their flairs, and a correlation between positive sentiments and higher user engagement. Additional analysis of demographics showed varied sentiment distributions across age and gender. We also extend the analysis to multi-class classification on Reddit, aiming to predict authors’ age and gender using NLP and ML techniques. We found that post sentiments varied minimally across age groups, predominantly featuring negative sentiments, with a significant concentration in the 18-25 age bracket. Gender analysis echoed this trend, with negative sentiments dominating all identified genders, as numerically validated by the gender sentiment distribution table. Furthermore, the data preparation for machine learning involved cleaning and transforming text through CountVectorizer, focusing on the most frequent words.
After identifying “NoStupidQuestions” as the subreddit that we would investigate for topics related to Covid-19 trends, we created a plot that should convey its interest over time in this particular subreddit. Separately, the research integrated Reddit submissions with classic literature texts, employing detailed NLP transformations and data filtering. This preparation will facilitate the development of the input data to train a recurrent neural network (RNN) that will generate new story submissions.
All sections used the John Snow Labs sparkNLP package to perform the text analysis. Please see the links to each section’s .ipynb notebooks for the specific implementation.
Analysis Report
Flair Sentiment Model
In this section, we explored the textual content of the r/AmItheA*hole (r/AITA) posts with respect to their assigned flairs and subsequently applied a pre-trained sentiment model. Using a sparkNLP pipeline, all text posts from r/AITA in 2022 with one of the four primary flairs (A*hole, Not the A*hole, Everybody Sucks, No A*holes Here) attached were processed/cleaned and run through a pre-trained sentiment model. The sentiment model most commonly assigned these posts a “negative” sentiment, as shown in Figure 1. This holds across posts assigned to any of the four primary flairs.
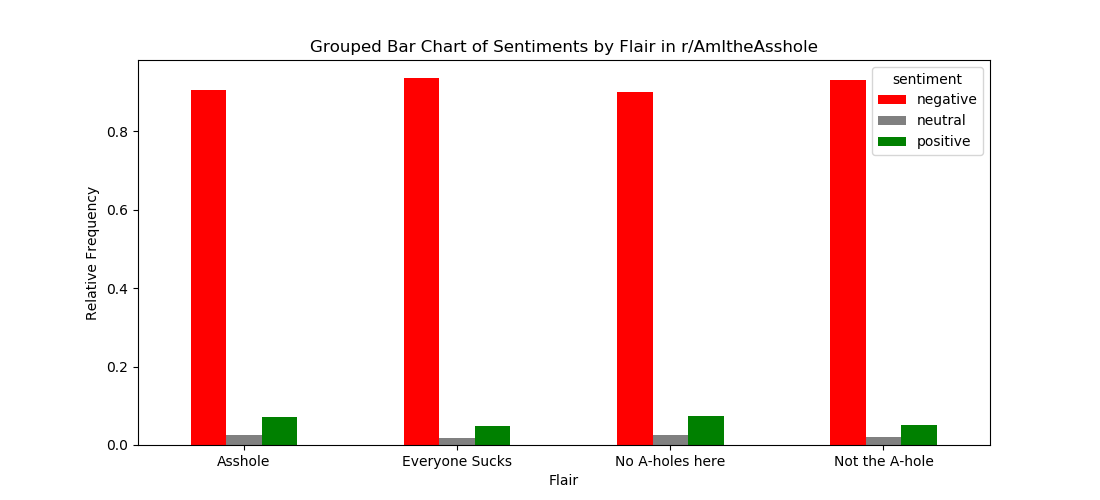
To further delve into the sentiments of these posts in r/AITA, we analyzed these sentiment assignments with respect to the engagement a post receives, represented by the number of comments under each post. In the Figure 2, the mean number of comments per post is grouped by flair assignment and sentiment assignment.
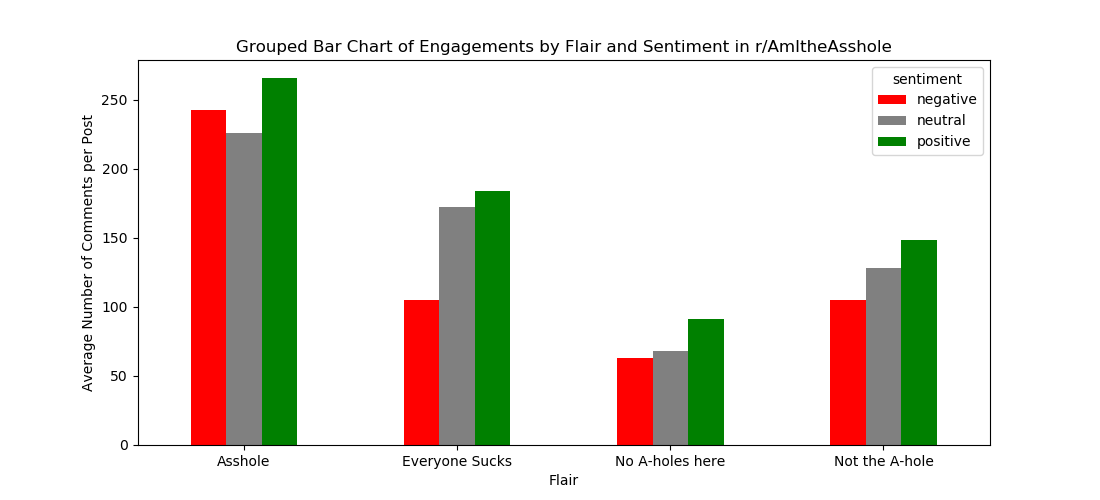
From this plot above, we can extract several conclusions. We can see that posts assigned the “A*hole” flair receive the most user engagement (on average), and posts assigned “No A-holes here” receive the least engagement, on average. Additionally, posts assigned a “negative” sentiment receive less user engagement than those with a “positive” sentiment across all four primary flairs. Thus, it is possible there could be a relationship wherein the more “positive” a post’s sentiment/writing is, the more likely it is to receive more engagement (at least in the form of the number of comments).
Table 1 below is a numerical representation of Figure 2 showing the average number of comments per post by flair and sentiment assignment.
| Flair | Negative | Neutral | Positive |
|---|---|---|---|
| Asshole | 242.2 | 225.59 | 265.44 |
| Everyone Sucks | 104.88 | 172.31 | 183.61 |
| No A-holes here | 63.15 | 67.74 | 90.92 |
| Not the A-hole | 105.07 | 128.07 | 148.4 |
The code used for this section is available here.
Extracting the age and gender of the author of the post
In using NLP and ML techniques to predict the age and gender of the author who created a post, it’s important to observe the distribution of ages and genders as they relate to other variables of interest. In particular, observing these variables as they relate to post sentiment can be interesting. Note that the age and gender of the post’s author are not provided in the dataset and are extracted from the post itself using Regex, if available.
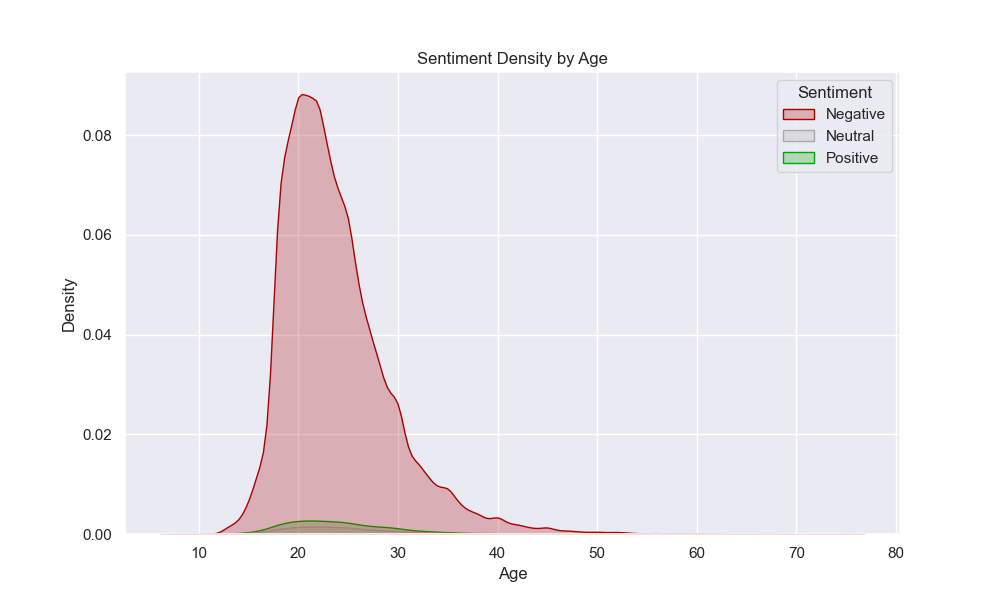
In Figure 3, we can see a density plot of the age of the author of a post, grouped by the categorized sentiment of the post itself. There doesn’t seem to be much difference between the distribution of ages for each sentiment, as each seems to peak around ages between 18 and 25 years old. Furthermore, we can see that most posts contain negative sentiment - likely posts written about negative experiences and asking for advice.
We can visualize similar features regarding the identified gender of the author of a post in Figure 4. Here, we can see the distribution of categorized sentiment of posts grouped by the identified gender of the post’s author. Again, the distribution of sentiments across genders is relatively similar, with most posts containing negative sentiment.
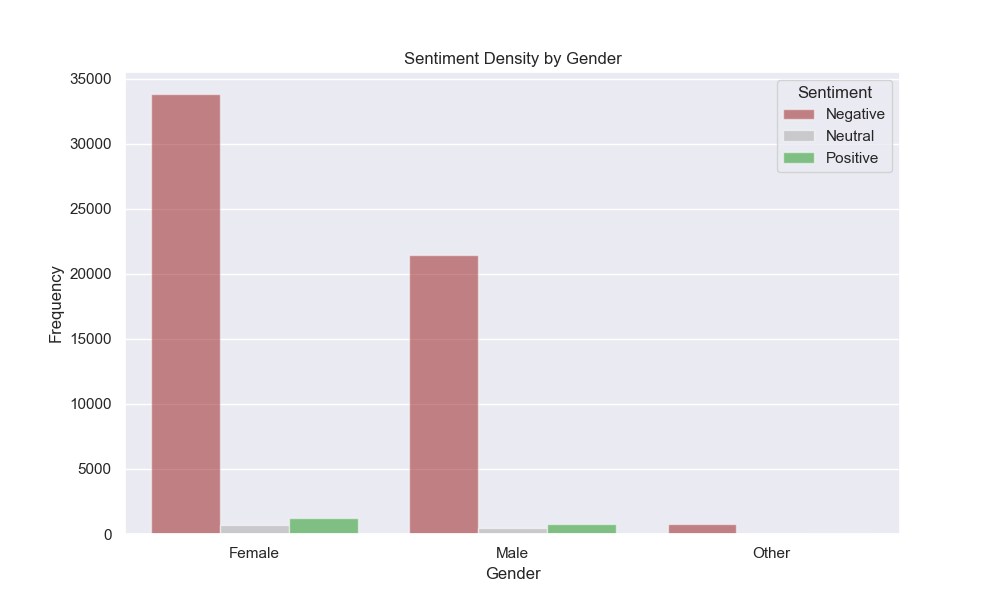
Table 2 represents the same data as above but expresses the relative frequencies of categorized post sentiment grouped by the author’s identified gender. Here, we find numerically that the distribution of sentiments is very similar across genders, with negative sentiments making up almost 95% of instances for all genders.
| Female | Male | Other |
|---|---|---|
| 0.95 | 0.95 | 0.93 |
| 0.02 | 0.02 | 0.02 |
| 0.03 | 0.03 | 0.05 |
NLP with CountVectorizer
To incorporate NLP-based predictors in a machine learning model, we first have to process the content of each Reddit post such that it can appropriately be fed into the model. Importantly, textual data cannot be sent directly into a machine learning model - we must represent the text numerically such that it can be interpreted by the model. One way in which we do this is by identifying how many times each word is used in each post.
In preparing the data for machine learning models, we first want to clean the textual data before representing it numerically. In doing so, we opt to perform the following cleaning steps:
- Remove all special characters, retaining only alphabetic characters and spaces: This will help us focus only on the words used rather than any punctuation present.
- Convert the text to lowercase: This will help us standardize word usage by interpreting capitalized and non-capitalized words as the same.
- Tokenize the text: This will help us break down posts into their individual word tokens rather than maintaining one long document.
- Remove “stop words”: This will help us remove extremely common words, such as “a” and “and”, so that we can focus more on the selective vocabulary that each author uses.
- Stem and lemmatize words: This will help us take different variations of the same word, such as “run”, “running”, and “ran”, and reduce them into the stem of the word (“run”).
In performing these cleaning steps, we obtain representations of the textual components of each post that we can begin to represent numerically. To do this, we conduct a few more steps:
- Calculate word frequencies: This will help us obtain a numeric representation for each word within each document - the number of times it occurs.
- Subset to the “n” most frequent words across all documents: This will help us filter out very uncommon words, including, but not limited to, misspelled words.
By obtaining word frequencies and subsetting the vocabulary to a more manageable size, we can retain a large portion of the total words used while greatly reducing the search space with respect to our vocabulary. For instance, the top 10% of the most frequently used words might make up 80% of the total words used, with most being used infrequently (Zipf’s Law).
Table 3 is a glimpse at what our transformed dataset looks like as it prepares to be sent into a machine learning model. We obtain “n” columns - one for each of the “n” most frequent words - with values representing the frequency with which they appear in each document. These features can be combined with other data features, such as the number of comments associated with a post, to form a feature set suitable for a machine learning model.
| Subreddit | ‘like’ | ‘feel’ | ‘want’ | ‘know’ | ‘time’ | ‘tell’ | ‘get’ | ‘im’ | ‘think’ | ‘friend’ |
|---|---|---|---|---|---|---|---|---|---|---|
| antiwork | 1 | 0 | 1 | 0 | 2 | 0 | 0 | 0 | 0 | 0 |
| unpopularopinion | 2 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| AmItheAsshole | 2 | 2 | 2 | 0 | 1 | 0 | 1 | 4 | 4 | 0 |
| NoStupidQuestions | 1 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 3 | 0 |
| TrueOffMyChest | 0 | 0 | 3 | 1 | 0 | 1 | 0 | 0 | 0 | 0 |
| relationship_advice | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| relationship_advice | 0 | 1 | 0 | 1 | 0 | 2 | 0 | 1 | 0 | 2 |
| NoStupidQuestions | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| relationship_advice | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| relationship_advice | 0 | 0 | 1 | 5 | 2 | 3 | 0 | 0 | 0 | 0 |
The code used for this section is available here.
Preparing Covid-19 data in NoStupidQuestions
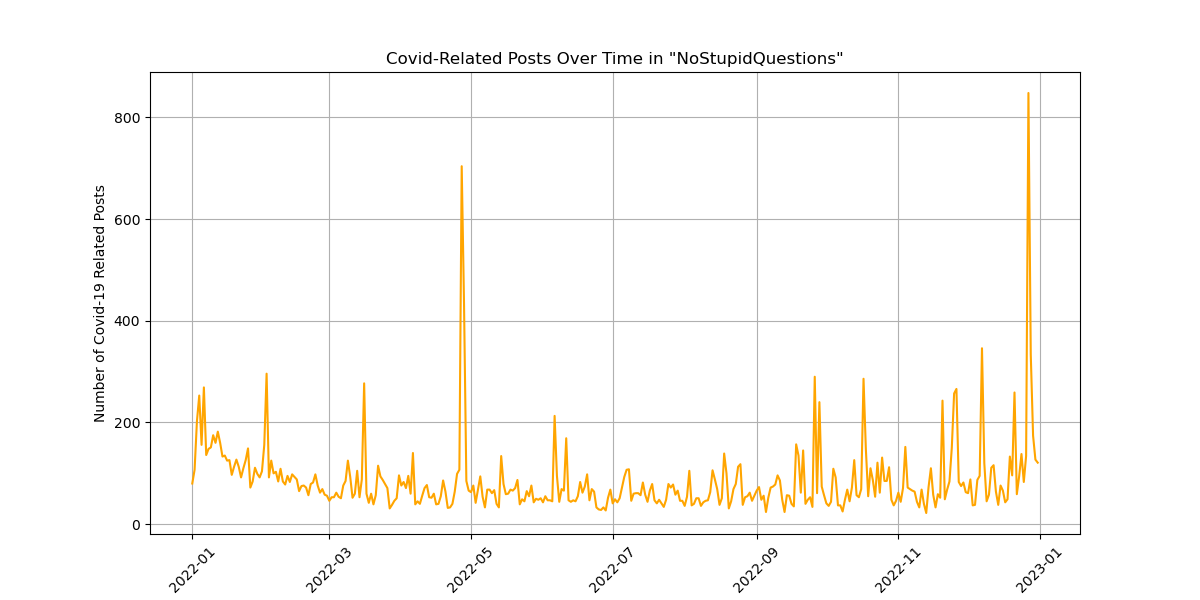
This section dove into understanding the relationship between COVID-19 and the subreddit r/NoStupidQuestions, over the timeframe of our data. After data cleaning and prep, keywords were used to find comments of interest from the “body” of a comment that had been tokenized and had stopwords removed. We then created the visualization below, Figure 5, to show how the engagement with this story changed over time. While there was no major consistent trend over time, engagement did seem to be higher early on and there are some spikes that might tell us about the dialogue around this story.
Data from this work will be used for further investigation in the ML portion of our project. There, we will use the comments we have just identified and a summarization model to summarize the top comments related to our chosen topic. This will hopefully give us a much more precise understanding of this topic.
The code used for this section is available here.
Preparing Reddit and External Data for Training an RNN
For this exercise, we focused on preparing text that contains great storytelling to train a Recurrent Neural Network (RNN) that can generate new stories. We use our 12 months of Reddit submissions data described in the EDA section for the analysis. Additionally, we integrate external data containing the text of famous stories from Project Gutenberg books that have stood the test of time, specifically The Scarlet Letter by Nathaniel Hawthorne [1], The Odyssey by Homer [2], Crime and Punishment by Fyodor Dostoyevsky [3], Metamorphosis by Franz Kafka [4], and The Great Gatsby by F. Scott Fitzgerald [5]. While the stories retrieved from Reddit have high scores, adding books from external sources ensures that our training data will contain storytelling that has stood the test of time and transcended generations. This may make the model more likely to output better, more compelling output.
To prepare the Reddit data, we extracted only the relevant information from the parquets, such as subreddit, title, selftext, score, and URL, and filtered out deleted or empty submissions. To select the best stories, we used a regular expressions pattern to remove any “Edit:” sections to remove post-edit additions that could skew the analysis. Since stories must be at least a few paragraphs, we removed all posts that didn’t have at least 4,500 characters (around 750 words). Then, we filtered for only stored with score in the top 85th percentile, focusing on submissions that garnered significant user interaction.
We then combined the text sources. The data underwent a series of NLP transformations, including custom tokenization and lowercasing, to prepare it for advanced analysis. We constructed a vocabulary and transformed the individual characters into tokens. The resulting frequency of each token is shown in Figure 6. Lastly, we stored the processed data in a structured Parquet format alongside the character-to-index mappings, crucial for the subsequent machine-learning modeling.
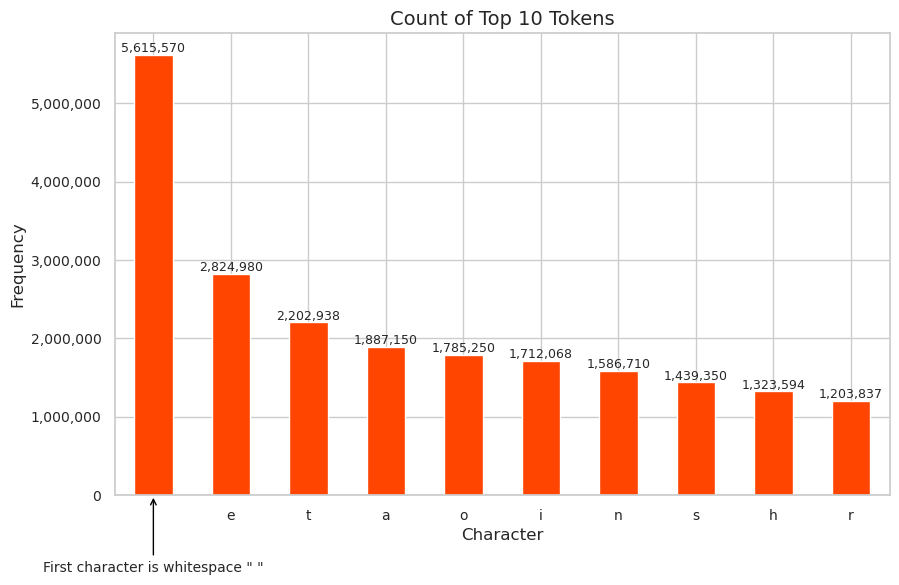
As an additional way to visualize the resulting dataset, we also can see the results of the top 10 N-Grams, where \(N=5\) in Table 4.
| 5-Gram (incl spaces) | Count |
|---|---|
| i was | 22,165 |
| and i | 17,933 |
| in the | 15,264 |
| of the | 13,807 |
| that i | 11,631 |
| to be | 10,346 |
| it was | 10,172 |
| to the | 9,418 |
| i had | 8,307 |
| i dont | 8,212 |
The code used for this section is available here.
The external data is available here.
Data Storage
Outputs of the NLP cleaning procedures are stored in .parquet format in the team bucket s3a://project17-bucket-alex/ for ease of use with ML models.