ML
Execution Summary
We embarked on a journey to uncover what truly resonates with Reddit users. Starting with the question of popularity, we built our first machine learning model to predict whether a post would become popular. The idea was simple: could emotional features explain why some stories capture attention while others fade into obscurity?
Phase 1: Predicting Popularity
We started by building our first machine learning model to predict popularity, focusing solely on the features of a post. Using emotional features we calculated—such as anticipation, regret, anger, and guilt—we wanted to explore whether emotions were the driving force behind a post’s success.
To test this idea, we trained three models: Logistic Regression, Random Forest, and Gradient Boosting. Among these, Gradient Boosting delivered the best performance, showcasing its ability to capture subtle patterns in the data. However, when we examined the feature importance, we noticed an interesting trend: all features had a weight below 0.2, indicating a limited influence on the predictions. Emotions like anticipation, regret, anger, and guilt stood out among all features, but they weren’t definitive indicators of popularity. This led us back to our original question: What truly resonates with users? While emotional features seemed significant, they didn’t fully capture the depth of engagement. The first model relied only on submission data, ignoring one crucial aspect of resonance—the audience’s reaction through comments.
Phase 2: Shifting Focus to Agreement
Recognizing this gap, we pivoted our focus to a new perspective: agreement. After all, resonance isn’t just about how many people like or upvote a post—it’s about whether the audience connects with its sentiment and content. This prompted us to develop a second machine learning model to predict agreement in comments.
To achieve this, we introduced a new process:
Labeling Comments: We trained a model to label comments as either “agree” or “disagree” based on their sentiment and tone using an outside dataset Debagreement (Pougué-Biyong et al. 2021).
Aggregating Agreement Scores: For posts with multiple comments, we calculated the average agreement score to assign an overall label of high, neutral, or low agreement to each submission.
Using these labels, we trained a second machine learning model, again incorporating emotional features along with metadata. This time, Random Forest outperformed other models, delivering the highest accuracy. But the results revealed something intriguing: the score column we had used in the first phase to measure popularity had little association with agreement.
One key challenge in the second phase was computational limitations. We were able to label only a portion of the comments, which reduced the number of submissions available for training. Despite this, the results reinforced an important takeaway: popularity isn’t the same as resonance. While score measures surface-level engagement, agreement captures a deeper emotional connection between the author and the audience.
Conclusion
This two-step exploration illuminated the complexity of resonance on Reddit. Popularity, driven by upvotes and comments, is only part of the story. By shifting our focus to agreement, we uncovered a richer layer of interaction that speaks to what truly connects users to the stories they read. This iterative journey from predicting popularity to modeling agreement has not only deepened our understanding of emotional resonance but also opened doors for further exploration into the dynamics of storytelling and engagement.
Analysis Report
Machine Learning on Popularity
Defining Popularity
To label posts as popular or unpopular, we utilized the Score metric from the original Reddit dataset.
Score Filtering: Posts with scores of 0 or 1 were removed as they lacked significant engagement.
Median Threshold: After filtering, the median score was calculated. Posts with scores above the median were labeled as popular (1), while those below were labeled as unpopular (0).
This binary classification of popularity formed the target variable for our machine learning models. However, the dataset presented a key challenge: imbalance. The number of unpopular posts far exceeded the popular ones, potentially skewing the model.
Balancing the Dataset
To address the imbalance:
We performed random sampling of unpopular posts to match the number of popular posts. This ensured the model was trained on a balanced dataset, reducing bias toward the majority class. With this dataset prepared, we moved forward to train multiple machine learning models to predict popularity based on post features.
Methodology
Feature Engineering
We utilized a range of features derived from the post content and metadata, including:
Text Features: Length of the post (text_length), sentiment scores (text_joy, text_anger, etc.), and emotional similarity metrics (e.g., selftext_regret_similarity).Metadata Features: Indicators like locked (whether the post was edited), over_18 (NSFW status), and title_length.Derived Features: emotion_alignment_score, which measures alignment between the post title and content sentiment.
Models
We implemented three machine learning models to predict post popularity:
- Logistic Regression: A simple linear model for comparison.
- Random Forest: A tree-based ensemble method leveraging feature importance for interpretability.
- Gradient Boosting: A powerful boosting algorithm designed for strong predictive performance.
Evaluation Metrics
To evaluate model performance, we used:
- Confusion Matrix: To understand true positives, true negatives, and misclassifications.
- ROC-AUC: To measure the models’ ability to distinguish between popular and unpopular posts.
- Feature Importance: To interpret which features contributed most to the predictions.
Results
Model Performance
Summary of Evaluation Metrics:
Accuracy: Gradient Boosting achieved the highest accuracy of 62.77%, indicating its superior ability to classify posts as popular or unpopular. Random Forest followed closely with an accuracy of 62.02%, while Logistic Regression lagged behind at 60.71%.
F1-Score: The F1-score, which balances precision and recall, shows a similar trend, with Gradient Boosting leading at 0.6139, followed by Random Forest (0.6005) and Logistic Regression (0.5930).
Precision and Recall: Precision, which measures the model’s ability to correctly identify popular posts, was slightly higher for Gradient Boosting (0.6394) and Random Forest (0.6374) compared to Logistic Regression (0.6152). Recall, which measures the ability to capture all popular posts, was highest for Gradient Boosting (0.6277%), slightly better than Random Forest (0.6202%) and Logistic Regression (0.6071%).
AUC (Area Under the Curve): Gradient Boosting and Random Forest performed similarly in terms of AUC (0.6425 and 0.6429, respectively), indicating good discrimination between popular and unpopular posts. Logistic Regression had a lower AUC of 0.6221.
Confusion Matrices
Random Forest: Balanced performance across popular and unpopular posts but struggled slightly with false negatives.
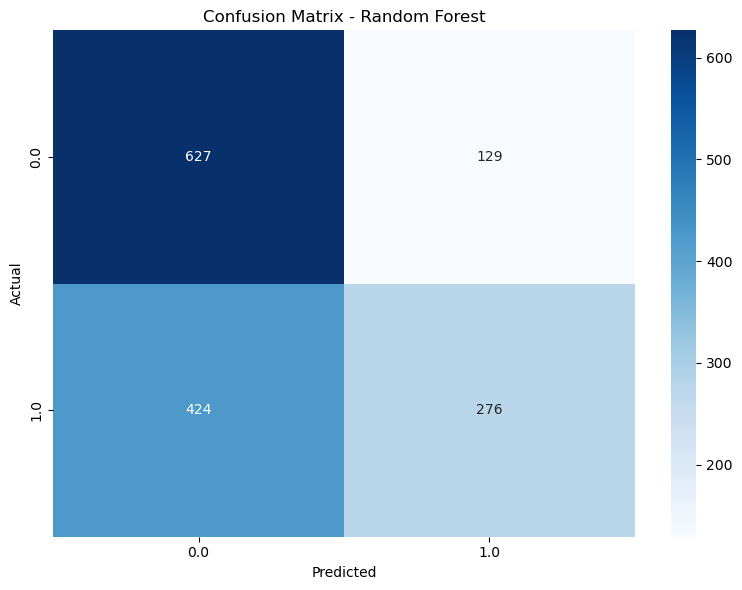
Figure 1: Figure 1: Confusion Matrices - Random Forest Logistic Regression: A higher rate of false negatives but good at identifying unpopular posts.
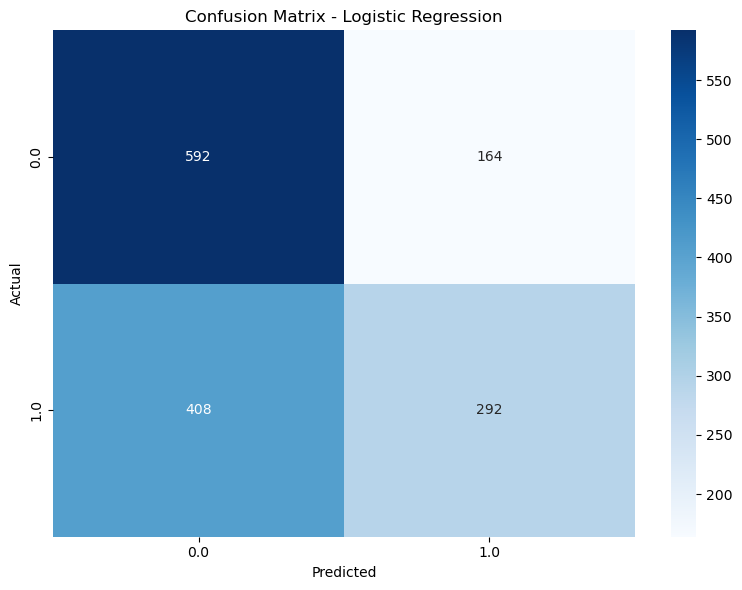
Figure 2: Figure 2: Confusion Matrices - Logistic Refression Gradient Boosting: Improved performance over Logistic Regression, with fewer false positives and better generalization.
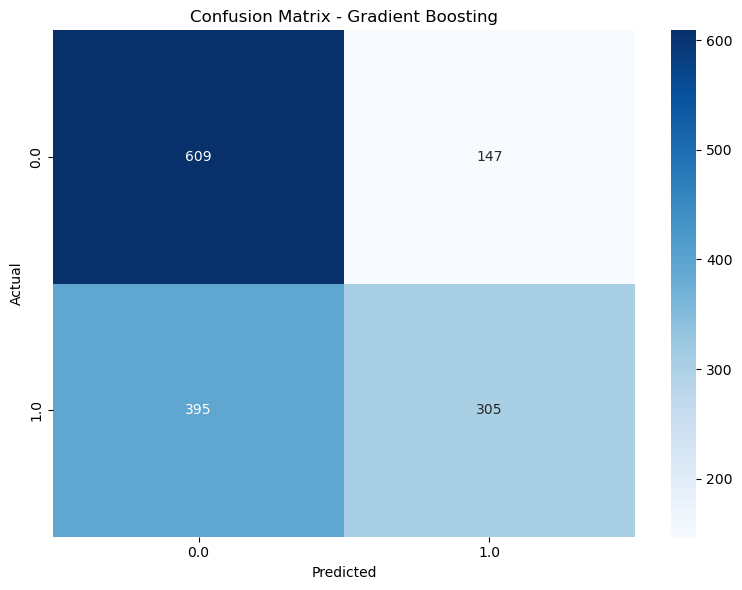
Figure 3: Figure 3: Confusion Matrices - Grandiant Boosting
ROC Curves
The ROC curves illustrate the models’ ability to classify popular and unpopular posts. Random Forest and Gradient Boosting achieved similar AUC scores (~0.643), outperforming Logistic Regression (AUC ~0.622). 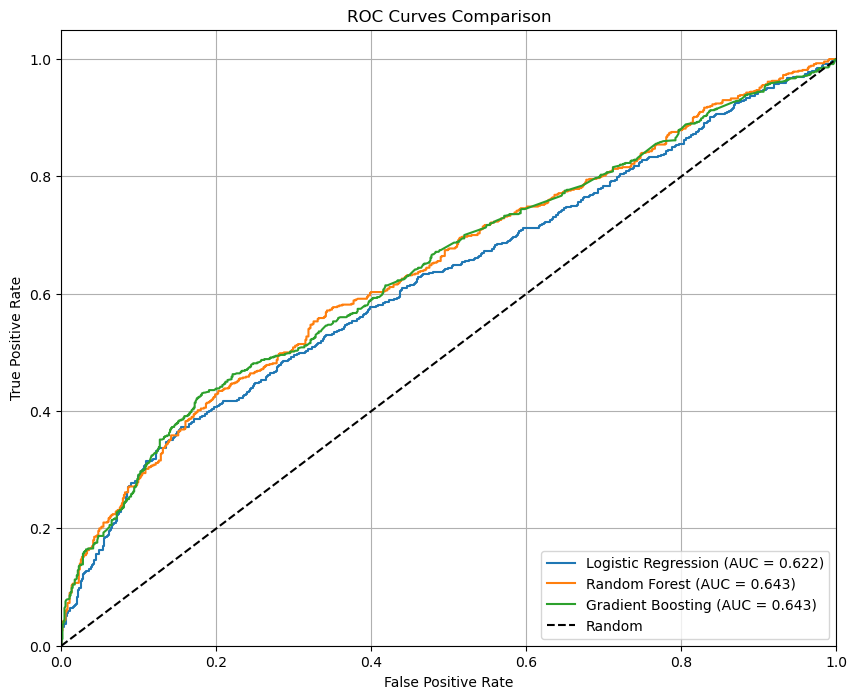
Feature Importance
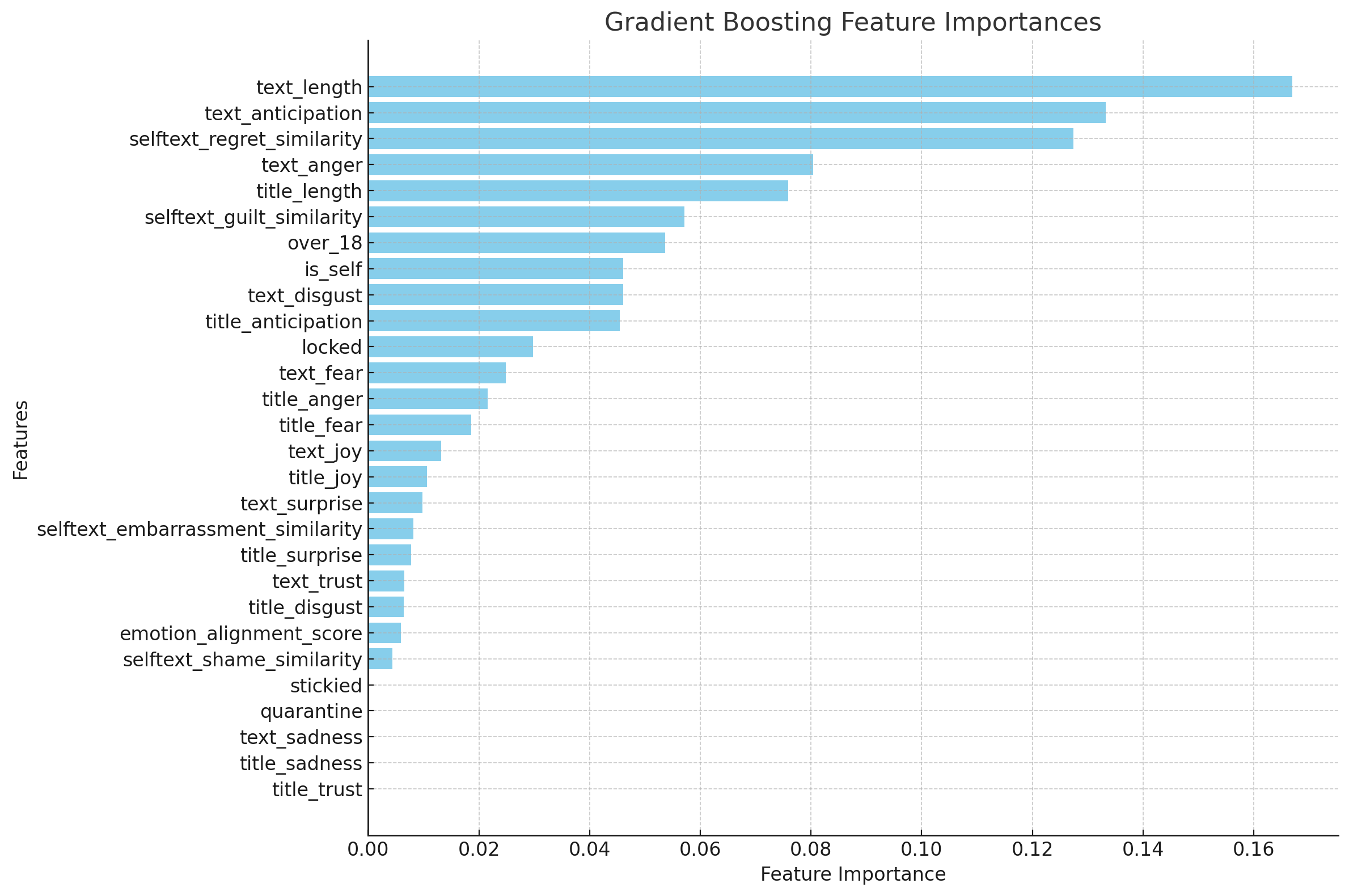
Gradient Boosting - Achieved highest accuracy
The most significant features included:
- text_length: Longer posts were more likely to become popular.
- text_anticipation: using lexicon for title emotion anticipation detection. Anticipatory tone in posts contributed strongly to popularity.
- selftext_regret_similarity: calculate the semantic similarity score of each submissions with word ‘regret’ using BERT. The emotional regret in posts contributed strongly to popularity.
- text_anger: Using lexicon for title emotion anger detection. Angeray tone in posts contributed strongly to popularity.
- title_length: Longer title were more likely to become popular.
Discussion and Insights
- Key Drivers of Popularity: Longer posts with an emotional tone, particularly anticipation and trust, were more likely to resonate with audiences.
- Challenges with Imbalanced Data: The initial imbalance skewed predictions, but random sampling helped mitigate this issue. Model Interpretability: Feature importance analysis revealed actionable insights into what makes a post popular, providing direction for content creators aiming to maximize engagement.
Machine Learning on Agreement
Defining Agreement
To investigate resonance beyond popularity, we introduced Agreement as the target variable. Agreement captures how well users align with the sentiment or content of a post based on comment reactions.
Steps to Define Agreement:
- Comment Labeling: Comments were labeled as agreeing or disagreeing using a trained classification model.
- Post-Level Agreement Scores: For each submission with multiple comments, an average agreement score was calculated based on the labeled comments.
- Threshold for Classification: Posts were classified as High Agreement (1) or Low Agreement (0) using the median agreement score as the threshold.
Balancing the Dataset
Similar to the first model, the dataset was imbalanced, with fewer posts showing high agreement. To address this, we:
- Randomly sampled low-agreement posts to match the number of high-agreement posts, creating a balanced dataset.
- Ensured the model could fairly learn patterns from both classes.
Methodology
Feature Engineering
For this model, we incorporated emotional and textual features from both posts and comments:
- Text Features: Sentiment scores (e.g., text_joy, text_anger), semantic similarity with key emotions (e.g., selftext_regret_similarity), and comment sentiment aggregation.
- Metadata Features: Variables such as locked, over_18, and title_length.
- Derived Features: Agreement-based metrics and emotion alignment between posts and comments.
Results
Model Performance Summary of Evaluation Metrics: * Accuracy: Random Forest achieved the highest accuracy (63.08%), outperforming Gradient Boosting (62.56%) and Logistic Regression (61.54%).
F1-Score: Random Forest led with an F1-score of 0.6311, indicating its strength in balancing precision and recall.
Precision and Recall: Precision and recall were highest for Random Forest, showing its ability to accurately classify high-agreement posts while minimizing false negatives.
AUC (Area Under the Curve): Random Forest had the highest AUC (0.678), followed by Gradient Boosting (0.661) and Logistic Regression (0.649), indicating strong discriminative power.
Confusion Matrices
Random Forest: Balanced performance with fewer false negatives and false positives.
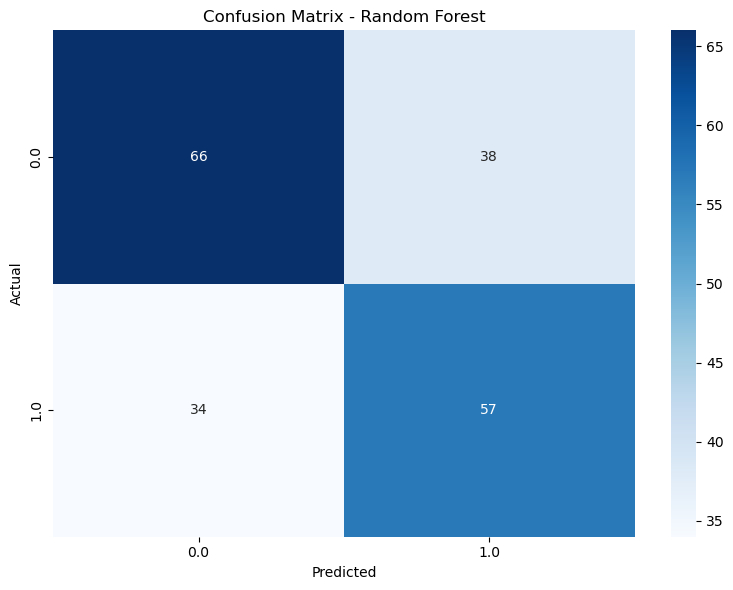
Figure 4: Figure 6: Confusion Matrices - Random Forest Gradient Boosting: Comparable to Random Forest but with slightly higher false negatives.
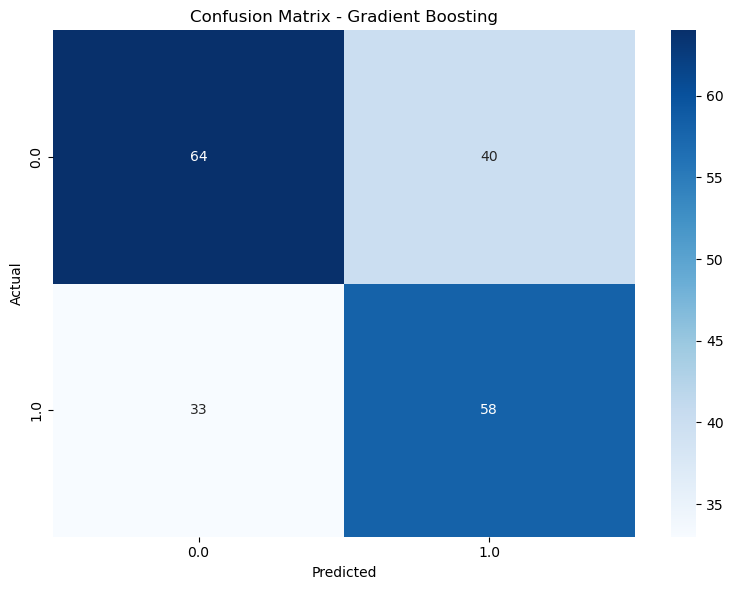
Figure 5: Figure 7: Confusion Matrices - Logistic Refression Logistic Regression: Struggled with classifying high-agreement posts, leading to higher false negatives.
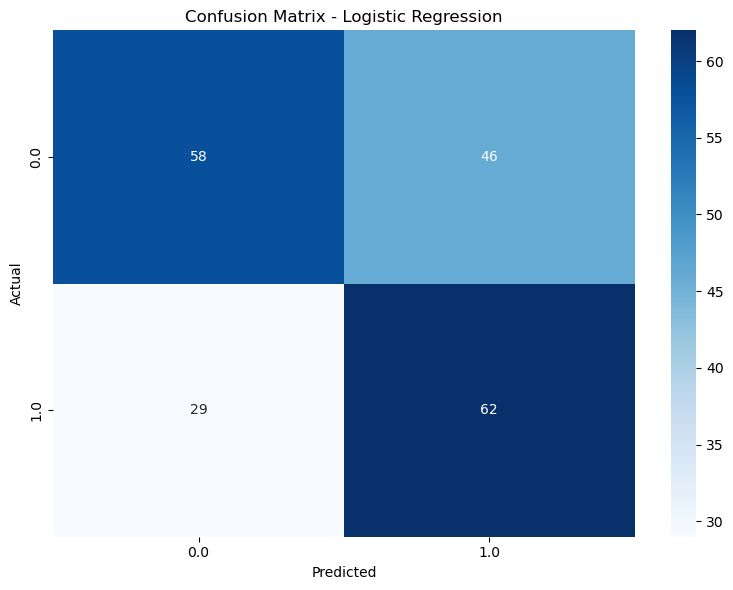
Figure 6: Figure 8: Confusion Matrices - Grandiant Boosting
ROC Curves
The ROC curves reveal the models’ ability to classify posts based on agreement. Random Forest achieved the best balance between true positives and false positives (AUC = 0.678). 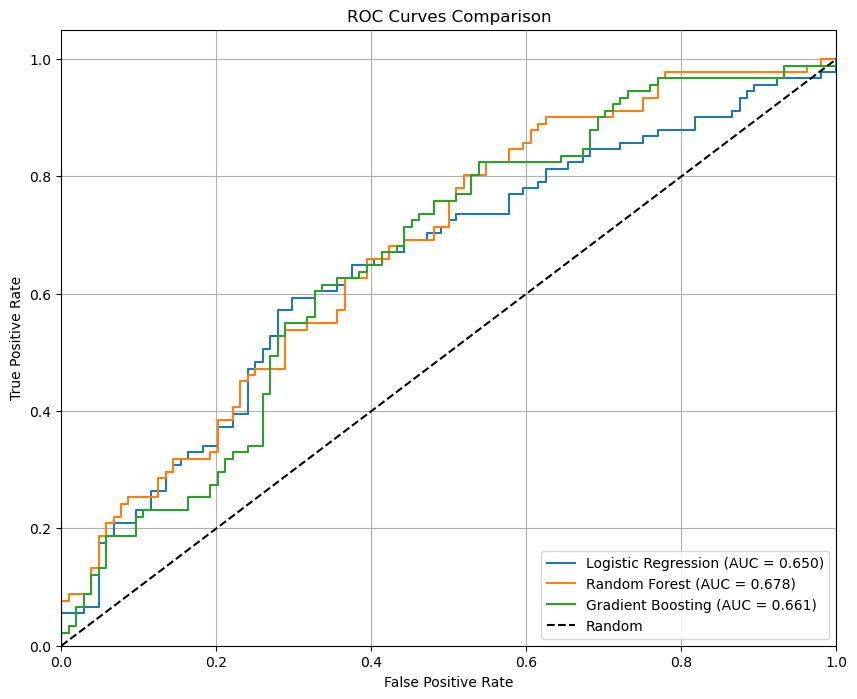
Feature Importance
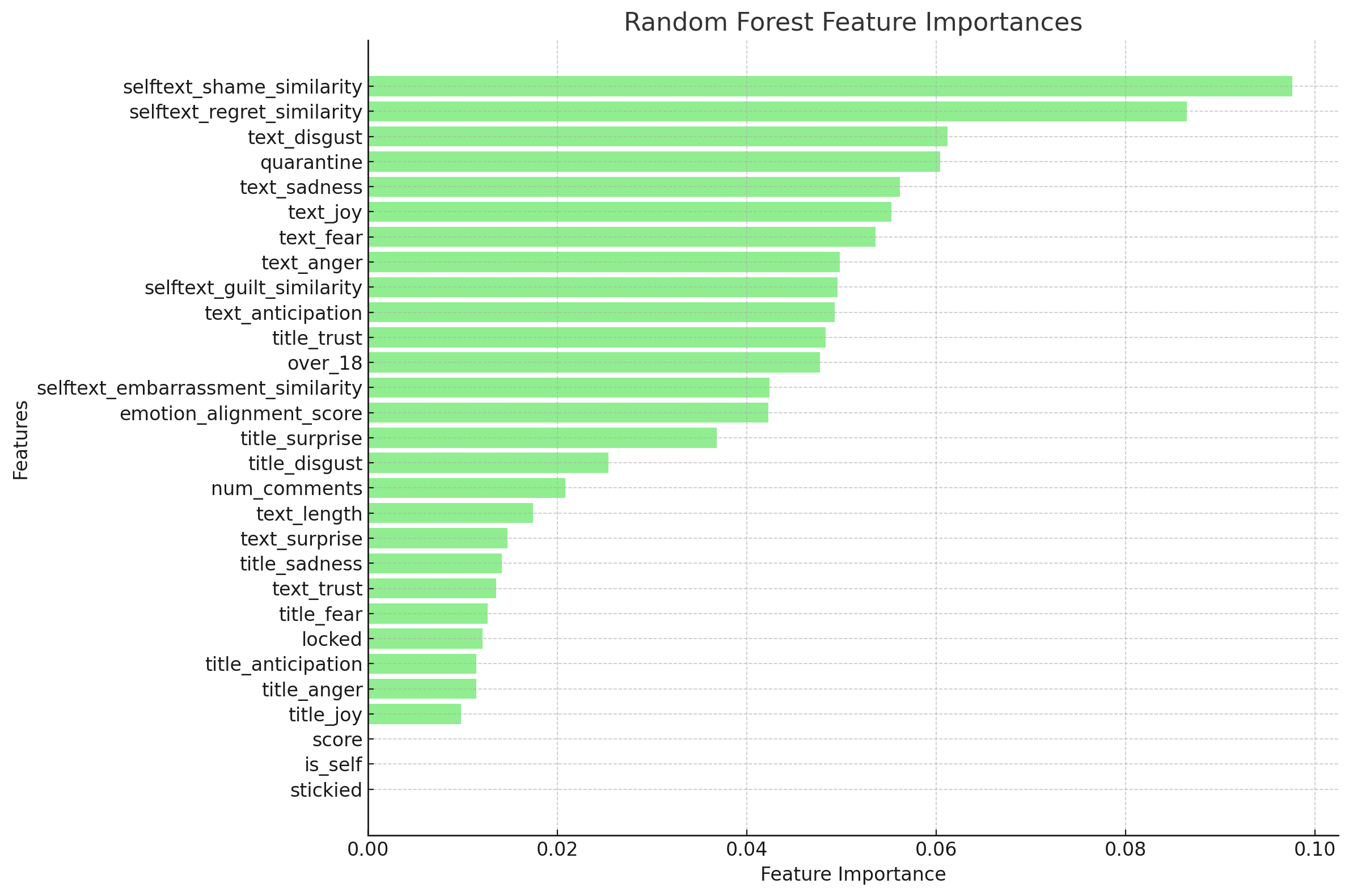
Random Forest - Achieved highest accuracy
Key predictors of agreement included:
- selftext_shame_similarity: Posts with emotional resonance in shame drove higher agreement.
- selftext_regret_similarity: Regret emerged as a critical factor for aligning with readers.
- text_disgust: Disgust in comments/posts influenced user agreement.
Discussion and Insights
- One notable observation from the feature importance plots is that the
scorecolumn—used as a proxy for popularity in our first machine learning model—has a near-zero importance value in predicting agreement. This suggests a weak association between popularity (as measured by score) and agreement among users. - Key Drivers of Agreement: Posts evoking emotions like shame, regret, and joy were more likely to garner agreement. This reinforces the importance of emotional alignment in user resonance.
- Model Performance: Random Forest stood out as the most effective model for predicting agreement, balancing accuracy, interpretability, and feature insights.
- Limitations: Computational constraints limited the size of labeled comments, impacting the generalizability of the results. Scaling up the labeling process would enable more robust modeling.